

Google brings new generative models to Vertex AI, including Imagen

To paraphrase Andreessen Horowitz, generative AI, particularly on the text-to-art side, is eating the world. At least, investors believe so — judging by the billions of dollars they’ve poured into startups developing AI that creates text and images from prompts.
Not to be left behind, Big Tech is investing in its own generative AI art solutions, whether through partnerships with the aforementioned startups or in-house R&D. (See: Microsoft teaming up with OpenAI for Image Creator.) Google, leveraging its robust R&D wing, has decided to go the latter route, commercializing its work in generative AI to compete with the platforms already out there.
Today at its annual I/O developer conference, Google announced new AI models heading to Vertex AI, its fully managed AI service, including a text-to-image model called Imagen. Imagen, which Google previewed via its AI Test Kitchen app last November, can generate and edit images as well as write captions for existing images.
“Any developer can use this technology using Google Cloud,” Nenshad Bardoliwalla, director of Vertex AI at Google Cloud, told TechCrunch in a phone interview. “You don’t need to be a data scientist or developer.”
Imagen in Vertex
Getting started with Imagen in Vertex is, indeed, a relatively straightforward process. A UI for the model is accessible from what Google calls the Model Garden, a selection of Google-developed models alongside curated open source models. Within the UI, similar to generative art platforms such as Midjourney and NightCafe, customers can enter prompts (e.g. “a purple handbag”) to have Imagen generate a handful of candidate images.
Editing tools and follow-up prompts refine the Imagen-generated images, for example adjusting the color of the objects depicted in them. Vertex also offers upscaling for sharpening images, in addition to fine-tuning that allows customers to steer Imagen toward certain styles and preferences.
As alluded to earlier, Imagen can also generate captions for images, optionally translating those captions leveraging Google Translate. To comply with privacy regulations like GDPR, generated images that aren’t saved are deleted within 24 hours, Bardoliwalla says.
“We make it very easy for people to start working with generative AI and their images,” he added.
Of course, there’s a host of ethical and legal challenges associated with all forms of generative AI — no matter how polished the UI. AI models like Imagen “learn” to generate images from text prompts by “training” on existing images, which often come from datasets that were scraped together by trawling public image hosting websites. Some experts suggest that training models using public images, even copyrighted ones, will be covered by the fair use doctrine in the U.S. But it’s a matter that’s unlikely to be settled anytime soon.
Google’s Imagen model in action, in Vertex AI. Image Credits: Google
To wit, two companies behind popular AI art tools, Midjourney and Stability AI, are in the crosshairs of a legal case that alleges they infringed on the rights of millions of artists by training their tools on web-scraped images. Stock image supplier Getty Images has taken Stability AI to court, separately, for reportedly using millions of images from its site without permission to train the art-generating model Stable Diffusion.
I asked Bardoliwalla whether Vertex customers should be concerned that Imagen might’ve been trained on copyrighted materials. Understandably, they might be deterred from using it if that were the case.
Bardoliwalla didn’t say outright that Imagen wasn’t trained on trademarked images — only that Google conducts broad “data governance reviews” to “look at the source data” inside its models to ensure that they’re “free of copyright claims.” (The hedged language doesn’t come as a massive surprise considering that the original Imagen was trained on a public data set, LAION, known to contain copyrighted works.)
“We have to make sure that we’re completely within the balance of respecting all of the laws that pertain to copyright information,” Bardoliwalla continued. “We’re very clear with customers that we provide them with models that they can feel confident they can use in their work, and that they own the IP generated from their trained models in a completely secure fashion.”
Owning the IP is another matter. In the U.S. at least, it isn’t clear whether AI-generated art is copyrightable.
One solution — not to the problem of ownership, per se, but to questions around copyrighted training data — is allowing artists to “opt out” of AI training altogether. AI startup Spawning is attempting to establish industry-wide standards and tools for opting out of generative AI tech. Adobe is pursuing its own opt-out mechanisms and tooling. So is DeviantArt, which in November launched an HTML-tag-based protection to prohibit software robots from crawling pages for images.
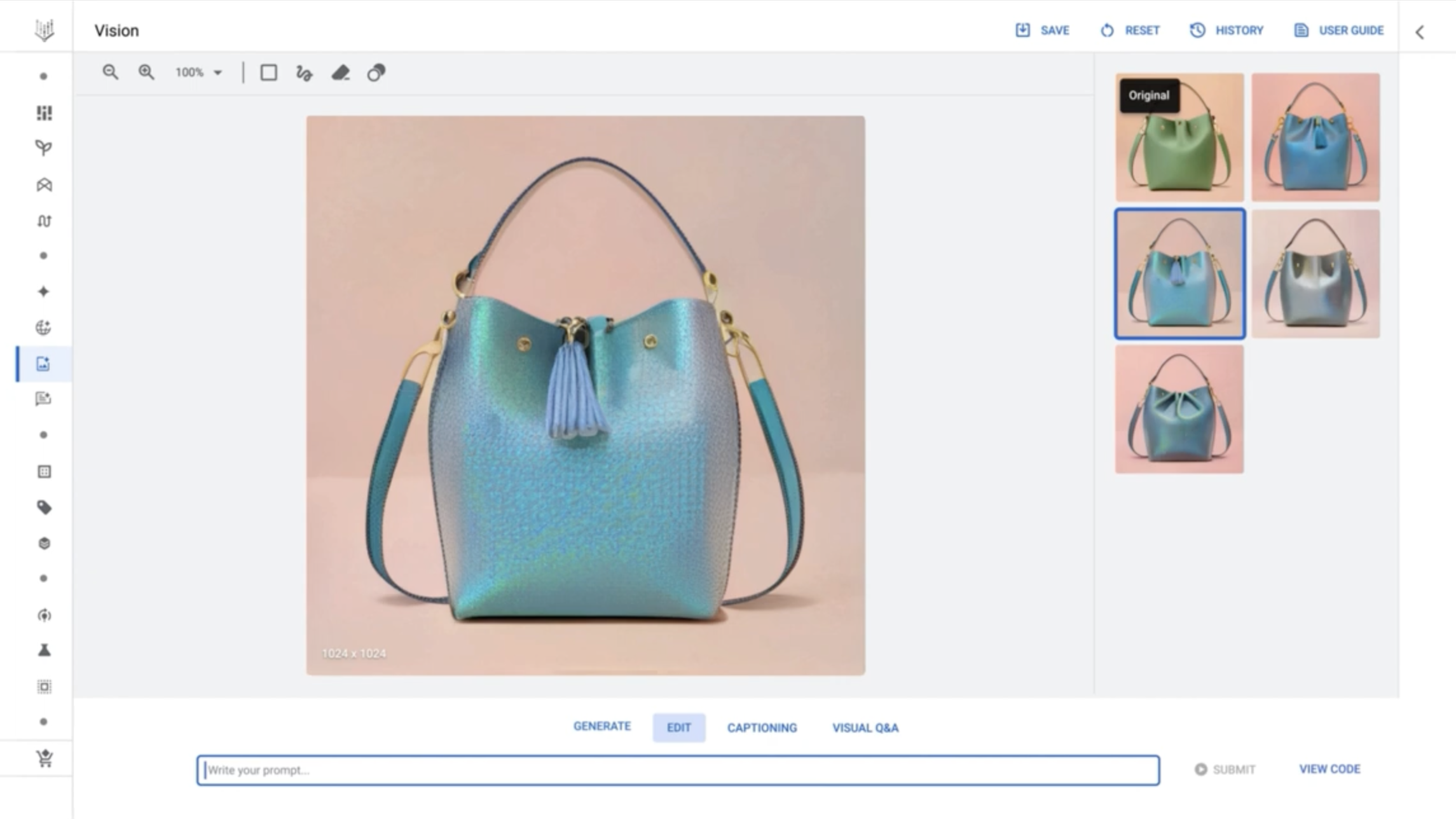
Image Credits: Google
Google doesn’t offer an opt-out option. (To be fair, neither does one of its chief rivals, OpenAI.) Bardoliwalla didn’t say whether this might change in the future, only that Google is “inordinately concerned” with making sure that it trains models in a way that’s “ethical and responsible.”
That’s a bit rich, I think, coming from a company that canceled an outside AI ethics board, forced out prominent AI ethics researchers and is curtailing publishing AI research to “compete and keep knowledge in house.” But interpret Bardoliwalla’s words as you will.
I also asked Bardoliwalla about steps Google’s taking, if any, to limit the amount of toxic or biased content that Imagen creates — another problem with generative AI systems. Just recently, researchers at AI startup Hugging Face and Leipzig University published a tool demonstrating that models like Stable Diffusion and OpenAI’s DALL-E 2 tend to produce images of people that look white and male, especially when asked to depict people in positions of authority.
Bardoliwalla had a more detailed answer prepped for this question, claiming that every API call to Vertex-hosted generative models is evaluated for “safety attributes” including toxicity, violence and obscenity. Vertex scores models on these attributes and, for certain categories, blocks the response or gives customers the choice as to how to proceed, Bardoliwalla said.
“We have a very good sense from our consumer properties of the type of content that may not be the kind of content that our customers are looking for these generative AI models to produce,” he continued. “This is an area of significant investment as well as market leadership for Google — for us to make sure that our customers are able to produce the results that they’re looking for that doesn’t harm or damage their brand value.”
To that end, Google is launching reinforcement learning from human feedback (RLHF) as a managed service offering in Vertex, which it claims will help organizations maintain model performance over time and deploy safer — and measurably more accurate — models in production. RLHF, a popular technique in machine learning, trains a “reward model” directly from human feedback, like asking contract workers to rate responses from an AI chatbot. It then uses this reward model to optimize a generative AI model along the lines of Imagen.
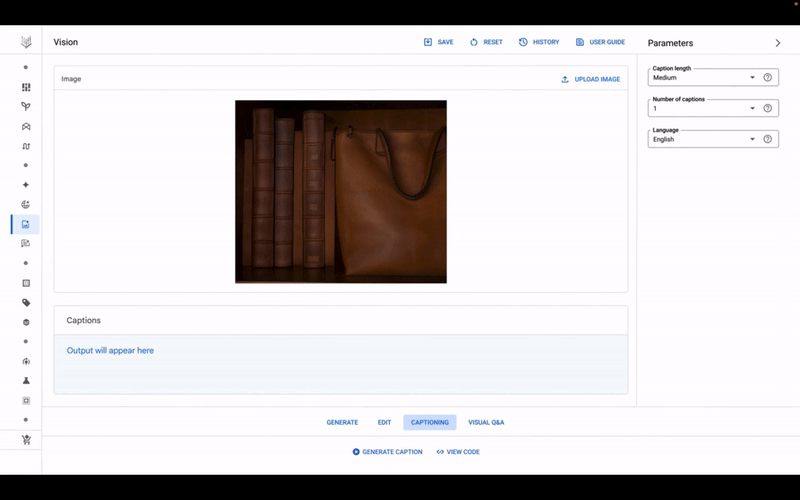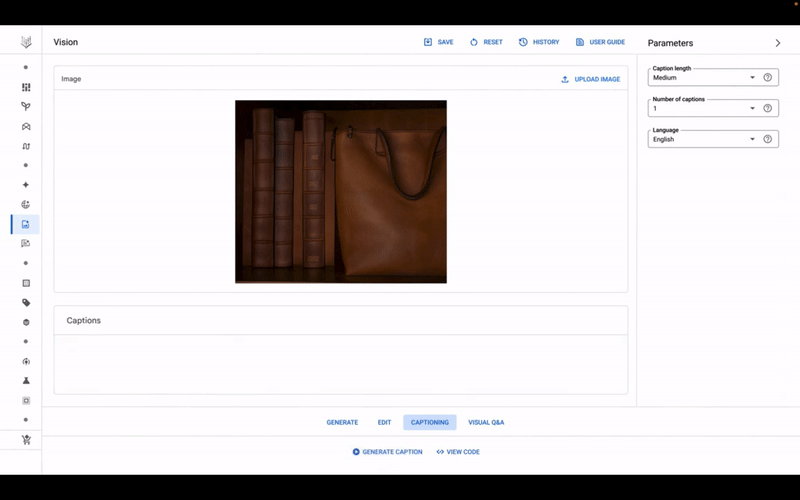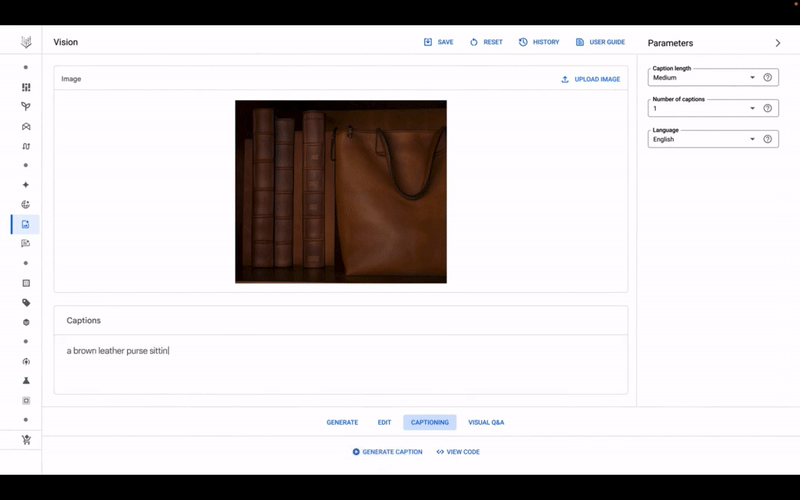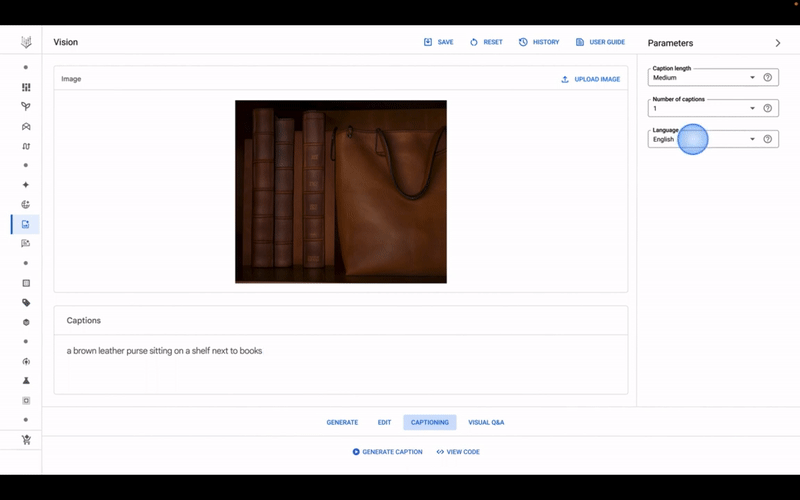
Image Credits: Google
Bardoliwalla says that the amount of fine-tuning needed through RLHF will depend on the scope of the problem a customer’s trying to solve. There’s debate within academia as to whether RLHF is always the right approach — AI startup Anthropic, for one, argues that it isn’t, in part because RLHF can entail hiring scores of low-paid contractors that are forced to rate extremely toxic content. But Google feels differently.
“With our RLHF service, a customer can choose a modality and the model and then rate responses that come from the model,” Bardoliwalla said. “Once they submit those responses to the reinforcement learning service, it tunes the model to generate better responses that are aligned with … what an organization is looking for.”
New models and tools
Beyond Imagen, several other generative AI models are now available to select Vertex customers, Google announced today: Codey and Chirp.
Codey, Google’s answer to GitHub’s Copilot, can generate code in over 20 languages including Go, Java, JavaScript, Python and TypeScript. Codey can suggest the next few lines based on the context of code entered into a prompt or, like OpenAI’s ChatGPT, the model can answer questions about debugging, documentation and high-level coding concepts.

Image Credits: Google
As for Chirp, it’s a speech model trained on “millions” of hours of audio that supports more than 100 languages and can be used to caption videos, offer voice assistance and generally power a range of speech tasks and apps.
In a related announcement at I/O, Google launched the Embeddings API for Vertex in preview, which can convert text and image data into representations called vectors that map specific semantic relationships. Google says that it’ll be used to build semantic search and text classification functionality like Q&A chatbots based on an organization’s data, sentiment analysis and anomaly detection.
Codey, Imagen, the Embeddings API for images and RLHF are available in Vertex AI to “trusted testers,” Google says. Chirp, the Embeddings API and Generative AI Studio, a suite for interacting with and deploying AI models, meanwhile, are accessible in preview in Vertex to anyone with a Google Cloud account.

Google brings new generative models to Vertex AI, including Imagen by Kyle Wiggers originally published on TechCrunch


